SUICIDE PREDICTION: A Socioeconomic Analysis
models implemented
1. XGBOOST
The model initially achieved a strong accuracy of 92.58%, with particularly high F1-scores of 0.93 and 0.95 for the "High" and "Low" classes, respectively, and a robust 0.89 for the "Medium" class. The macro and weighted averages of 0.93 indicated consistent performance, though the confusion matrix revealed challenges with the "Medium" class, where fewer true positives were identified. Fine-tuning slightly decreased accuracy to 91.27%, with marginal declines in precision, recall, and F1-scores across all classes, especially the "Medium" class, where the F1-score dropped from 0.89 to 0.87. Despite stable performance for the "High" and "Low" classes, the confusion matrix showed an increase in false negatives for the "Medium" class. These results suggest the model was already highly optimized before fine-tuning, with limited room for improvement, as the fine-tuning process prioritized optimization for the "Low" class at the expense of a minor drop in performance for others.
PERFRormance metrics for XGBOOST:


Accuracy:


Precision recall curve:


Transformation
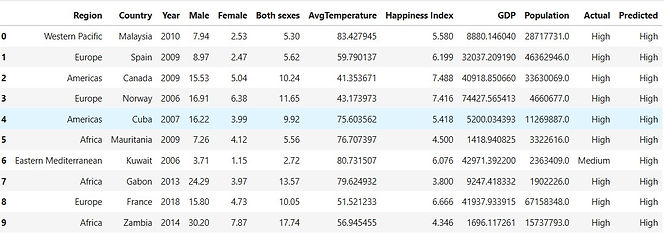
Original dataset:

Before fine-tune:

after fine-tune:

2. RANDOM FOREST MODEL
The Random Forest model performed exceptionally well, achieving 93.4% accuracy before fine-tuning and improving to 93.9% after optimization. Key features driving predictions included Population (35%), GDP (25%), and Average Temperature (20%), with the Happiness Index contributing less (15%). Fine-tuning improved recall for the "Medium" risk class from 75% to 77% and its F1 score from 81% to 83%, addressing previous misclassifications while maintaining ~95% precision and recall for the "High" risk level. The enhanced model is balanced and reliable, with potential for further improvement through advanced ensemble methods or interpretability-focused techniques.
pERFRormance metrics for random forest:





Transformation
Original dataset (Before fine-tune):

after fine-tune:
3. K- nearest neighbours
The KNN model showed outstanding performance, achieving 96% accuracy, precision, recall, and F1 score before fine-tuning, demonstrating its reliability for sensitive tasks like suicide risk prediction. Visual insights, including an ROC curve with an AUC of 0.99 and a precision-recall curve with consistently high values, validated its strong class discrimination. Key features contributing to predictions were Country_Encoded, Region_Encoded, and Happiness Index, while Population had the least impact. After fine-tuning, the model achieved 97% accuracy with optimal parameters (n_neighbors=3, Manhattan distance, uniform weights), improving recall for the at-risk class and ensuring fewer false negatives. This fine-tuned model remains a robust and practical solution, with future potential in exploring advanced models for enhanced interpretability and performance.
pERFRormance metrics for K- nearest neighbours:





Transformation
Original dataset (Before fine-tune):
after fine-tune:

4. Light gbm
The LightGBM model achieved an initial test accuracy of 87%, with precision, recall, and F1 scores of 86%, showcasing its ability to capture patterns even with default parameters. After fine-tuning hyperparameters like estimators, learning rate, and tree depth, the model improved to 91% accuracy and 90% precision, recall, and F1 scores, reducing misclassifications and enhancing generalization. Visualizations like feature importance plots and confusion matrices highlighted key predictors and showed balanced improvements after tuning. Additional tools, such as SHAP values and correlation heatmaps, provided deeper insights into feature interactions, confirming LightGBM as a reliable and interpretable classification tool with scope for further optimization.
pERFRormance metrics for Light gbm:


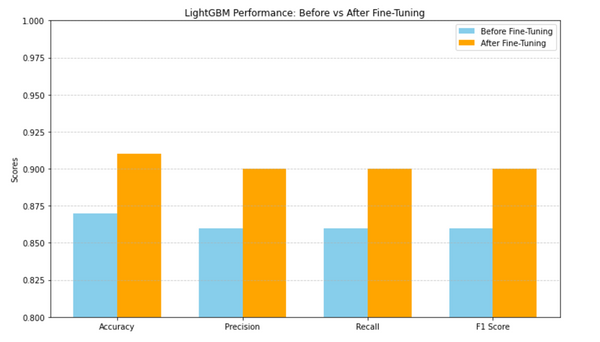
Transformation
Original dataset (Before fine-tune):
.jpeg)
after fine-tune:
.jpeg)
5. Support vector machine
The Support Vector Machine (SVM) model initially struggled with low accuracy (34%) and class imbalance, failing to effectively identify low and medium-risk classes. After fine-tuning through grid search for hyperparameter optimization, including adjustments to the kernel type, regularization parameter (C), and kernel coefficient (gamma), the model's performance significantly improved. Accuracy rose to 81.7%, with precision, recall, and F1-score also increasing from 11.6% to 81.8%, 34.1% to 81.7%, and 17.3% to 81.3%, respectively. The confusion matrix revealed more balanced classification, especially for the "Low" class, which achieved a 97% recall, and the "Medium" class showed notable improvements. While some misclassifications occurred in the "High" class, the overall results highlight the importance of hyperparameter optimization and preprocessing, suggesting that further improvements might require techniques like oversampling, undersampling, or class-weight adjustments to better handle all classes.
pERFRormance metrics for SVM:



Transformation
Original dataset:
Before fine-tune:

after fine-tune:
